

Unlocking Spotify's Recommendation Algorithm: The Hidden Mechanics of Machine Learning:
Discover how your listening habits shape personalized music suggestions through advanced data processing ...
👋 Hi there, my name is Alberto. I’m the writer on the NotNull newsletter, where I share some insights about data, tech and some build in public projects. Feel free to explore this and the rest of the free content.
Thank you for reading NotNull and enjoy the reading!👉 If you are in a hurry, the TL;DR (Too Long; Didn’t Read) will help!
TL;DR:
Spotify’s recommendation system combines raw audio analysis, user behavior, playlist patterns, and metadata to build detailed profiles of songs and listeners. It uses machine learning models to generate candidate tracks and a ranking algorithm to personalize suggestions in real time. By blending content-based and collaborative filtering, Spotify continuously adapts to your taste and context, offering tailored music experiences across features like Discover Weekly, Daily Mix, and Autoplay.

Table of Content
Introduction
Spotify’s Recommendation Architecture Overview
User Data Ingress: Capturing Listening Behavior
Content-Based Analysis of Tracks
Collaborative Filtering: Learning from Listening Patterns
Matching Users with Music: Spotify’s Recommendation Algorithms
Introduction
Machine learning is a powerful technology that makes sense of vast amounts of information, yet its inner workings often seem complex and mysterious. When experts explain Spotify’s recommendation system, it might feel as if a secret is being revealed. In reality, they are showing how data-driven models interpret the information available. This article shares some of those answers – along with the data behind them – to help every Spotify listener become a more informed user of music recommendations.
For transparency’s sake, note that this is not a literal blueprint of Spotify’s system. We focus on broad, evidence-based explanations rather than every secret ingredient. Approximately 40% of Spotify’s recommendations occur on-device, and the overall architecture is continually evolving. What we describe are the major components as understood today; details may change as we refine our approach. With that in mind, let’s explore the architecture behind Spotify’s recommendations.
Spotify’s Recommendation Architecture Overview
The “secret” behind Spotify’s music recommendations lies in our multi-stage architecture. It is a complex pipeline of interconnected platforms (or phases) that ingest your inputs, process them with an array of models, and output a set of suggested songs or artists tailored for you. In essence, your data flows through these stages – known in machine learning as data ingress – and is processed by numerous models working in parallel, ultimately producing a ranked list of tracks we think you’ll enjoy. Broadly, Spotify’s recommendation engine addresses the same challenge as any recommender system (be it Netflix or Amazon): matching the right items to the right users at the right time. To accomplish this, the system must understand both the content (songs) and the users. In Spotify’s case, it’s all about generating rich track representations and combining them with user taste profiles.
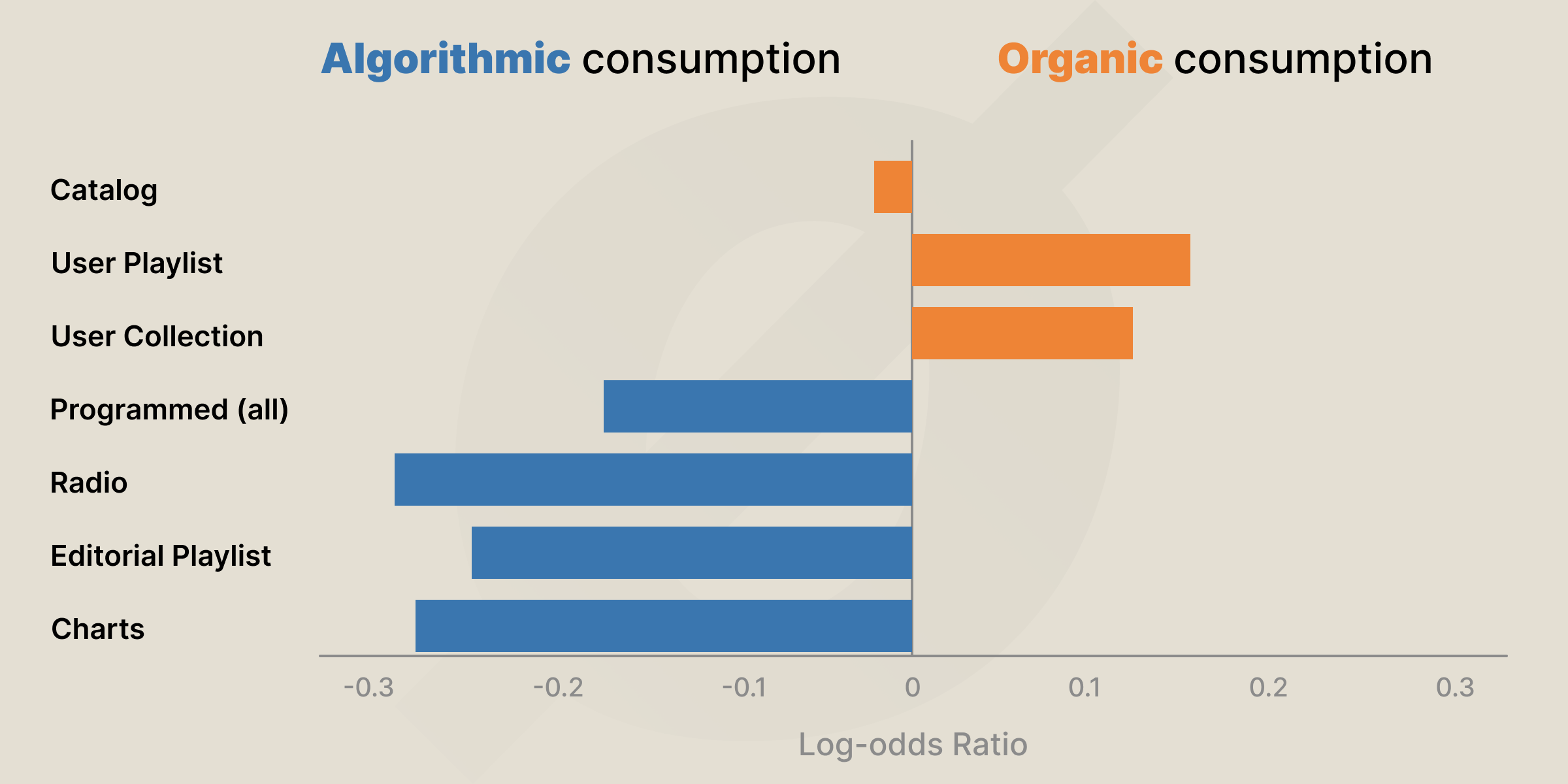
At a high level, Spotify’s system can be viewed as having two main analytical components that feed into the recommendations:
Content-based analysis – describing each track by examining the content itself (the audio and associated information).
Collaborative filtering – describing each track based on how it is consumed, i.e. its relationships with other tracks via user listening behavior.
The recommendation engine needs insights from both methods to build a holistic picture of every song and to tackle the “cold start” problem for new tracks. Once we have an understanding of the music and the listener, a final recommendation stage matches users with tracks. Let’s dive into each part of this pipeline.
User Data Ingress: Capturing Listening Behavior
The process begins with the inputs you give to Spotify, combined with what we know from your past activity. Each user interaction provides a continuous stream of signals about your context and preferences. We can think of these inputs in two categories: prompts and attributes. Prompts are the direct inputs you provide through the app – for example, searches you type in, songs you play or skip, playlists you create, and any likes or shares. Attributes are system-logged context data, such as your device type, whether you’re online or offline, your subscription tier, and general location. Together, these form a dynamic real-time representation of your current listening session. While prompts capture what you’re doing, attributes tell us the circumstances (for instance, streaming over Wi-Fi at home vs. on cellular while commuting).
We don’t rely on real-time signals alone. Spotify’s system also pulls in your accumulated historical data to interpret your tastes. This includes which artists you follow, your library of saved songs and albums, and the tracks you’ve played most often. All this information contributes to your user taste profile, which is essentially a personalized model of your musical preferences. Importantly, the context of your listening behavior is taken into account when building this profile. The recommendation engine logs your activity in context-rich listening sessions. This means it evaluates your actions with an understanding of why you might be listening. For example, if you are browsing the “What’s New” section to sample fresh releases, rapidly skipping songs there is expected behavior – you’re quickly scanning for anything interesting. In that context, a skip isn’t a strong negative signal. On the other hand, if you hit skip on a track while listening to a calming “Deep Focus” playlist, it suggests that track isn’t fitting your mood, which is taken as a stronger indicator of dislike.
All the feedback you generate can be split into two types: explicit feedback and implicit feedback. Explicit (active) feedback includes things you do intentionally, such as clicking the heart button to save a song, adding a track to one of your playlists, sharing a song, following an artist, or deliberately skipping a track. Implicit (passive) feedback is derived from your listening habits without extra action on your part – for instance, how long you let a song play (did you listen through or tune out early?), whether you replay songs, and the overall length of your listening sessions. In Spotify’s user profiling, explicit feedback is generally weighted more heavily. This is because music is often playing in the background; you might let a song continue simply because you’re busy (not necessarily because you love it). So when you actively do something, like saving a track, it sends a very clear signal of preference.
All of these user signals are processed to update your profile. The profile captures your favorite artists and songs, the genres and moods you gravitate towards, and even more nuanced traits like whether you tend to enjoy popular mainstream hits or prefer niche discoveries. It also observes temporal patterns – for example, maybe you lean towards mellow indie music on Sunday mornings, but pump energetic hip-hop on Friday nights. In fact, the system can segment your taste profile by context, recognizing that the same user has different musical personas for different moments. The end result is a rich, context-aware user model that continually evolves with your listening. As you explore new artists or genres and provide positive feedback on them, the system adapts to include those in your recommended mix – even if they differ from your old favorites.
Content-Based Analysis of Tracks
While the user profile describes who you are and what you like, the content-based filtering describes what each song is in detail. The goal here is to algorithmically “listen” to and characterize the music itself. As soon as a new track is ingested into Spotify’s catalog, our algorithms analyze a variety of information attached to it. One part of this is metadata – the descriptive tags and credits that come with a track. This includes obvious fields like the song title, artist name, album, release date, and genre, as well as richer metadata (when provided by artists/labels via Spotify for Artists) such as mood tags, explicit genre/subgenre tags, the primary language of the lyrics, the instruments used, whether it’s an original song or a cover, and so on. In an ideal scenario, all these metadata fields are correctly filled out and fed into our system. This artist-sourced metadata is then passed downstream into the recommendation pipeline, where it can inform other models (for instance, knowing the genre or the artist’s hometown could influence how we categorize the track in our recommendations).
However, metadata alone only scratches the surface of what a song truly sounds like. The second step of content-based filtering is analyzing the raw audio itself. The precise methods Spotify uses for audio analysis are a closely guarded aspect of our recommendation engine, but public information and research give a good idea of how it works. In fact, Spotify exposes some audio analysis results via its Web API – known as audio features – which provides concrete clues. These audio features are metrics that describe the sonic characteristics of a track. Many are fairly objective, such as the estimated tempo or the instrumentalness of the song (i.e. the confidence that the track has no vocals, on a scale from 0 to 1). But in addition to these, Spotify’s algorithms generate at least a few higher-level perceptual audio features that try to quantify the overall feel or vibe of the music. Notably, three of the key audio features available are:
Danceability – describes how suitable a track is for dancing based on musical elements like tempo, rhythm stability, beat strength, and overall regularity.
Energy – represents a perceptual measure of intensity and activity. A track with high energy might have a loud, fast, and noisy sound, whereas a low-energy track could be softer or more relaxed. This metric is computed from factors such as dynamic range, perceived loudness, timbre, and onset rate.
Valence – describes the musical positiveness or mood of a track. Songs with high valence sound more positive (happy, euphoric, cheerful), while low valence indicates a more negative or somber tone (sad, angry, depressed).
These features give a holistic sense of a song’s mood and style. And they are just one part of the audio analysis. The system doesn’t stop at single-number descriptors; it also examines the structure of the track over time. Another algorithm processes the raw audio file to understand its temporal composition, splitting the song into sections and segments of varying granularity. For example, it can identify higher-level sections like verses, choruses, bridges, or solos by detecting significant shifts in the music’s timbre or rhythm. It can zoom in down to very fine segments – even tatums, which are the smallest perceptible rhythmic subdivisions (essentially, fractions of a beat). This detailed breakdown allows the system to follow how the musical characteristics evolve throughout the track, not just what they are on average.
Over the past decade, audio analysis technology has advanced dramatically, and Spotify’s capabilities in this area have grown accordingly. The audio features exposed in the public API (like danceability, energy, etc.) date back to around 2013 and originate from Spotify’s acquisition of The Echo Nest. Today, internally, the platform likely computes a much richer set of audio descriptors than what is publicly visible. For instance, a Spotify research paper from 2021 mentions feeding a 42-dimensional audio feature vector into a recommendation model. That implies our system could be extracting on the order of dozens of distinct audio characteristics from each track’s raw signal (far more than the handful of features in the API). Furthermore, Spotify’s research teams have explored advanced audio analysis techniques like using machine learning for source separation (isolating individual instruments or vocals from the mix) and pitch tracking & melody estimation. If such techniques are deployed in production, the recommender system could literally deconstruct a song into its constituent parts – identifying the drum patterns, the guitar riffs, the vocal melody, chord progressions, etc., and analyze each in context.
In practice, all these audio analysis components allow Spotify to form an incredibly detailed profile of each track’s sound. We can discern not only obvious things (e.g. “this song has no vocals and a fast tempo”) but also higher-order patterns and compositional structure. The final output of the audio analysis might read like a musicologist’s report: for example, “this song follows a verse-chorus-verse structure, builds up in energy toward a bridge, then drops to a mellow outro with an acoustic guitar solo”.
In essence, the system can reverse-engineer much of what’s happening in the music – nearly as if it had a human listening attentively or a producer inspecting the track in a digital audio workstation. This content-based understanding of songs, comprising the metadata, the audio-derived features, and even related content like lyrics or cover art (in modern systems, text and images around a song can also be embedded as vectors), forms one pillar of Spotify’s recommendation engine.
Collaborative Filtering: Learning from Listening Patterns
The other pillar of Spotify’s recommendation strategy is collaborative filtering, which leverages the wisdom of the crowd. While content-based analysis tries to describe the song itself, collaborative filtering describes a song by its relationships with other songs and with listeners. Spotify was a pioneer in applying collaborative filtering to music, popularizing what’s often called the “Netflix approach” to recommendations. The basic idea is straightforward: if users with similar taste to you all tend to enjoy a certain track you haven’t heard, chances are you might like it too. In practice, the algorithm looks at patterns in listening histories across millions of users. A simplified example goes like this: say user A and user B have both listened heavily to songs X and Y. If user A also enjoyed a song Z that user B hasn’t heard yet, the system might recommend Z to user B. By maintaining a huge matrix of users and the tracks they listen to, collaborative filtering can identify song-to-song similarities (e.g. track Z is similar to track X because people who play X often also play Z) and user-to-user similarities (user B is similar to user A because of their overlapping taste).
However, the naive “user-item matrix” approach comes with challenges in a music context. Issues of scalability and cold start aside, one problem is that simply having overlapping listeners doesn’t always mean two songs are truly similar in a meaningful way. People’s listening habits can be very eclectic, and popular artists (think Metallica and ABBA) might share a broad listener base despite being nothing alike in style. To address this, Spotify has evolved its collaborative filtering to dig deeper into how users organize music, rather than just what they play. In particular, the platform found a richer signal in playlist data. Instead of only asking “who listens to what,” the system also asks: “which songs are frequently added to the same playlist or played in the same session?” If a lot of users independently group song A and song B together in their playlists, that’s a much stronger indicator that those two songs have something in common, compared to merely being listened to by some of the same people. Playlist-based collaborative filtering captures an element of context – it hints at why songs go together (for instance, they might share a mood or theme that makes people curate them in the same mix).
Spotify leverages an enormous corpus of user-generated playlists to train its collaborative filtering models. Reportedly, one of Spotify’s large-scale collaborative models was trained on a sample of about 700 million user playlists. These aren’t just random playlists either – Spotify selected them based on signals of “passion and care,” meaning playlists that users spent time curating (as opposed to auto-generated or throwaway lists). By learning from such a vast and thoughtfully curated dataset, the system uncovers a complex network of song relationships. It learns, for example, that a niche indie rock track might frequently appear on the same playlists as a certain folk song – revealing a subtle connection in vibe or audience, even if the two tracks don’t sound obviously similar. Meanwhile, two hip-hop tracks that sound alike might not be deemed similar by collaborative filtering if listeners use them in entirely different contexts or playlists.
By combining the collaborative signals with the content-based analysis, Spotify develops a holistic representation of each track. The content-based models provide an understanding of the song’s intrinsic qualities (audio characteristics, metadata, etc.), and the collaborative filtering provides an understanding of the song’s associations and appeal among listeners. Together, these portrayals enrich the track’s profile further by inferring higher-level descriptors – things like likely genre classification, mood tags, or even usage context (e.g. “good for workouts” or “fits into 80s nostalgia”) can be deduced from the patterns in the data. In recent years, Spotify’s track representations have become extremely granular and multi-dimensional, almost like building blocks of attributes that similar songs share. This means the system can easily deconstruct and recombine attributes to satisfy specific queries or scenarios. (For instance, you can search for “new chill French instrumental hip-hop” and the system can parse that into components and find songs that match all those criteria.)
Matching Users with Music: Spotify’s Recommendation Algorithms
Once we have rich representations of both the users and the tracks, the final step is to actually make the match – generating and ranking recommendations. Under the hood, most large-scale recommender systems (Spotify included) follow a two-stage approach at this point. The first stage is candidate generation (or retrieval), where the system pulls a pool of potential song recommendations for the user. These candidates might come from various models operating in parallel. In Spotify’s case, dozens of specialized models are likely at work. Some models generate candidates by looking for songs that are similar to what you already like (using the content-based audio and metadata features). Others generate candidates by looking at what users with similar tastes enjoy (using collaborative filtering patterns). There are models focusing on recent trending songs, on new releases by artists you like, on contextual signals (e.g. what fits the time of day or your current activity), and so on. Each model in this inference phase gives a set of tracks along with a confidence score – essentially, “How likely is the user to enjoy this?” based on that model’s criteria. As our Senior Director of Machine Learning likes to say, “Different models make different types of predictions, which leads to a variety of signals for each item.” Each model is capturing a unique aspect of the music-user relationship, and all are producing their best guesses in parallel.
The second stage is ranking. At this point, we have a large collection of candidate songs (often hundreds) with various scores from different models. The role of the ranking algorithm (sometimes called the ranker) is to sift through these and produce the final ordered list of recommendations you see. The ranker operates in the cloud and takes into account all the signals from the previous stage. It doesn’t just naively trust one model – it uses a sophisticated ensemble approach to weigh and combine the evidence. In Spotify’s system, we employ ensemble learning (models whose inputs include outputs of other models) and contextual reweighting, meaning the ranker can adjust how it combines signals based on the current context and what it knows about you. There are several sub-components and “adjuster” mechanisms that help refine the ranking before it reaches you, including:
Re-ranker: a model that takes the preliminary list of candidates and re-orders or filters them by learning the best way to consolidate all the input signals and the latest user context into a coherent list.
Multi-perspective rankers: a set of expert models, each focusing on a different perspective of what a “good” recommendation looks like. For example, one might prioritize overall similarity to your known tastes, while another might prioritize introducing some fresh but relevant discoveries. These multiple perspectives ensure diversity and balance in suggestions.
User-adapted combine models: models that adjust the weighting of different recommendation signals dynamically for each user. In other words, the system “learns how to learn” for you – it might discover that you respond more to audio-based similarities than popularity trends, so it will give more weight to the audio feature model’s suggestions in your case, for instance.
Preference adjusters: these models fine-tune recommendations according to specific personal preferences or quirks inferred about you. For instance, if you seem to favor songs around a certain tempo or you often listen to very long tracks, the system can tilt recommendations toward those preferences. Likewise, if you have a strong aversion to explicit lyrics and usually skip such tracks, a preference adjuster might down-weight recommendations that are tagged explicit.
When you open Spotify or refresh your Home screen, this whole process happens swiftly. The recommendation engine assembles your personalized list of tracks – often within just a few milliseconds – by running your current inputs through the network of models and applying the ranker to output the top results. By the time the app interface loads, you have a set of suggestions (e.g. songs, artists, or playlist recommendations) waiting, live-calculated for that moment. This pipeline is also continuously reactive. As you give new feedback (playing, skipping, saving tracks), the models update their understanding; the next batch of recommendations will reflect those changes, sometimes adapting in nearly real-time. It’s worth noting that not everything is recomputed from scratch server-side – some recommendation logic can even operate on-device. In fact, roughly 40% of Spotify’s recommendations are delivered via on-device computations. This means your phone or computer is doing part of the work (using cached data or lightweight models) to instantly suggest the next song, especially in features like radio autoplay where latency needs to be minimal.
Behind the scenes, the recommendation algorithms driving different Spotify features (Discover Weekly, Daily Mix, Radio, etc.) each have their own specific tuning and objectives. But they all draw from the same foundational user and track representations. For example, the algorithm that creates your Time Capsule playlist (throwbacks to songs you used to love) relies heavily on the user–track affinity signals – it looks for tracks you once listened to a lot but haven’t heard in a while. Discover Weekly’s algorithm, by contrast, emphasizes a mix of affinity and similarity – it finds songs that are similar to your current tastes but that you haven’t heard yet. A feature like Daily Mix might first cluster your listening preferences into distinct sub-groups (e.g. your jazz favorites vs. your indie rock favorites) and then expand each cluster with new, similar tracks. Despite these differences, the core process remains: generate candidates, then rank them with an ensemble of signals tuned to the context. The final list aims to satisfy your immediate interests while also aligning with Spotify’s broader goals (such as keeping you engaged and helping you discover new music you enjoy).
Conclusion
What some listeners perceive as almost “magical” – that uncanny ability of Spotify to queue up just the right song – is in fact the product of a highly engineered system of data and algorithms. Understanding this system requires a technical explanation, but it doesn’t have to be a black box. By peeling back the layers of Spotify’s recommendation architecture, we see that it’s built on logical components: ingesting rich user context, analyzing the content of millions of tracks, learning from the collective behavior of listeners, and then stitching these pieces together with machine learning models that balance many factors. Our architecture continually learns from each play, skip, and playlist edit, adjusting to your evolving taste in near real-time. While we haven’t revealed every detail (and indeed, the platform keeps improving and changing), we’ve outlined the general framework that powers your music suggestions. We hope this brings a bit more transparency to the process – demystifying the “secret” behind the recommendations, and illustrating that there’s a method to the music.
Ultimately, Spotify’s recommendation engine is designed with a simple goal: to reliably deliver songs you’ll love, at the right moment, while still surprising you with new discoveries – all through the careful marriage of data, machine learning, and the universal language of music.
Source: Algorithmic Effects on the Diversity of Consumption on Spotify

You can support us by subscribing to the free plan, liking, sharing, and commenting on our articles. We’d like to know how we are doing.
We Love Data :)